
수술 전 마취 위험을 빠르고 정확하게 예측할 길이 열렸다. 이형철·윤수빈 서울대병원 마취통증의학과 교수 및 이현훈 국가전략기술 특화연구소 교수팀은 71만여명의 수술 데이터를 바탕으로 수술 전 마취 위험을 예측하는 인공지능 모델을 개발하고, 성능을 검증한 결과를 28일 발표했다.
 이형철(왼쪽부터)·윤수빈 서울대병원 마취통증의학과 교수, 이현훈 국가전략기술 특화연구소 교수
이형철(왼쪽부터)·윤수빈 서울대병원 마취통증의학과 교수, 이현훈 국가전략기술 특화연구소 교수
연구팀은 마취 전 평가 요약문을 바탕으로 환자의 수술 위험을 평가하는 거대언어모델(LLM)을 자체 개발했다. 이를 활용하면 신속하고 객관적인 수술 위험 평가를 통해 의료서비스의 질을 향상할 수 있을 것으로 기대된다.
수술 전 마취 위험을 평가하는 과정은 환자의 안전을 위해 매우 중요하다. 국내 의료 현장에서는 환자의 전반적인 건강상태를 1등급(건강한 환자)부터 6등급(뇌사 상태)으로 구분하는 ‘미국마취과학회 신체상태 분류’(American Society of Anesthesiologists physical status classification, ASA-PS)를 도입해 마취 위험과 전반적인 수술 위험의 예측 도구로 널리 활용하고 있다.
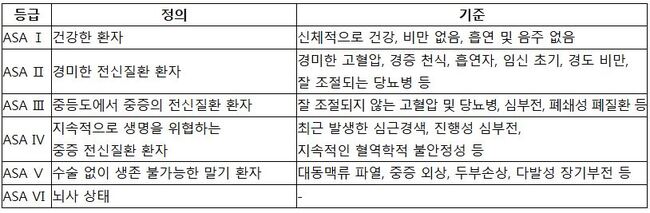 ASA-PS 분류 체계 그러나 ASA-PS 체계는 중증도 기준이 주관적이어서 의료진 간 ASA-PS 등급 분류가 불일치하는 문제가 종종 발생했다. 의료서비스를 효율적으로 제공하려면 중증도 마취 위험을 일관적·객관적으로 파악할 수 있는 수술 전 평가 도구가 필요했다.
ASA-PS 분류 체계 그러나 ASA-PS 체계는 중증도 기준이 주관적이어서 의료진 간 ASA-PS 등급 분류가 불일치하는 문제가 종종 발생했다. 의료서비스를 효율적으로 제공하려면 중증도 마취 위험을 일관적·객관적으로 파악할 수 있는 수술 전 평가 도구가 필요했다.
연구팀은 이런 문제를 해결하기 위해 2004~2023년 서울대병원에서 수술 받은 71만여명의 대규모 환자 데이터를 학습시켜 ASA-PS 등급을 자동 분류하는 거대언어모델을 개발했다. 이 모델은 사람의 언어를 이해하는 챗GPT처럼 자연어처리 기술을 기반으로 하는 인공지능으로, 특히 의료기록과 개인정보 보안에 특화돼 있다.
이 거대언어모델을 활용하면 환자의 건강상태·기저질환 등을 간략하게 서술한 ‘마취 전 평가 요약문’을 바탕으로 ASA-PS 등급을 신속하고 객관적으로 분류할 수 있다. 따라서 임상 현장에서 의사소통의 효율성과 환자 안전을 증진하는 데 도움이 될 수 있다는 것이 연구팀의 설명이다.
환자 460명의 데이터를 바탕으로 분류 성능을 평가한 결과, 모든 ASA-PS 등급에 대한 이 모델의 평균 예측 정확도(AUROC)는 0.915로 매우 높았다. 이 수치가 1에 가까울수록 완벽한 예측을 했음을 의미한다.
또 거대언어모델 및 마취과 전문의 분류 성적은 각각 특이도(0.901 vs 0.897), 정밀도(0.732 vs 0.715), F1-점수(0.716 vs 0.713)로, 모두 거대언어모델이 조금씩 우수한 성능을 보였다.
F1-점수는 정밀도(모델이 양성으로 예측한 것 중 실제 양성 비율) 및 재현율(실제 양성인 것 중 모델이 양성으로 예측한 비율)의 조화평균을 말한다.
추가적으로 임상적 의사결정에 중요한 ASA-PS 1~2등급(건강한 사람 및 경미한 전신질환)과 3등급 이상(중증도 전신질환 이상)의 환자를 구분하는 데 거대언어모델의 오류율은 11.74%로, 이는 마취과 전문의의 오류율 13.48%보다 우수한 성적이었다.
이형철·윤수빈 교수는 “이 연구 결과는 인공지능 기술이 임상 현장에서 실질적으로 활용될 수 있음을 보여주는 성과”라며 “후속 연구를 통해 환자의 안전 및 의료 질 향상에 기여할 수 있는 기술을 지속적으로 개발할 수 있도록 노력하겠다”고 말했다.
이현훈 교수는 “인공지능 수술 전 마취 위험 평가 모델이 세계적으로 활용될 수 있도록 특화연구소의 데이터를 바탕으로 세계적으로 협력하면서 글로벌 기술사업화를 추진해나갈 계획”이라고 말했다.
이번 연구는 디지털 헬스케어 분야의 네이처 파트너 저널 ‘디지털 메디신’(npj Digital Medicine, IF;12.4) 최근호에 게재됐다.

 목록
목록

























